The Node.js Event Loop
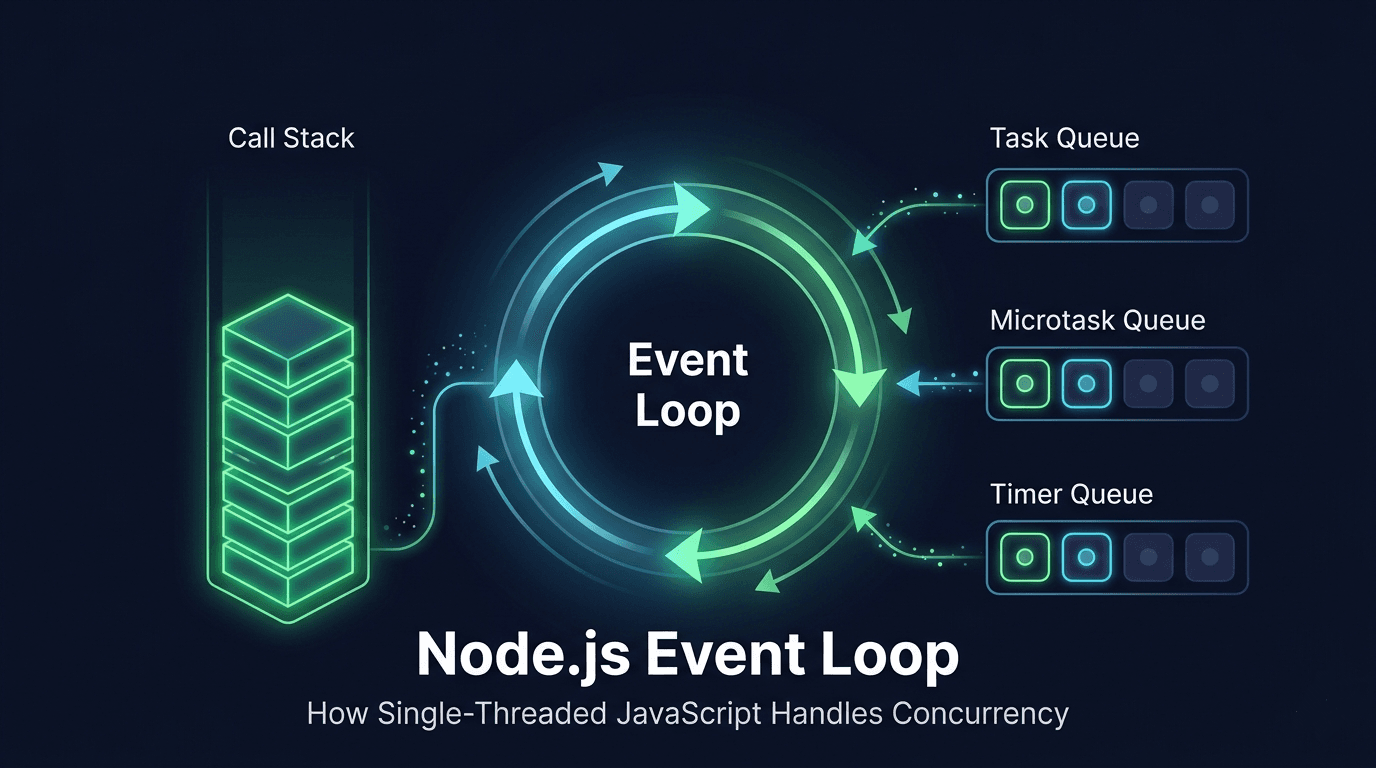
We all know that the Node.js runs on single threaded architecture, still it handles thousands of concurrent operations, and this makes us think.... How is that even possible ?
The answer can be found in one of the most important concept of Node.js : The Event Loop.
In this article we are going to understand everything about Event loop and it's internals in detail.
The Problem :
Javascript was originally designed for browsers, an environment where only one UI thread runs at a time.
Node.js inherited the same model, this means Node.js can only execute one piece of code at any given point of time. There is no parallel execution of JS code by default.
This is not good for any web server, imagine 1000 users hit your server at the same moment, and each request requires a 2 seconds to complete the databse query. A traditional multi-threaded server would spin a new thread for each request, means 1000 threads running in parallel. It works, but it is expensive, each thread will also consume memory (roughly 1-2 mb), and coordinating between threads will increase complexity.
Node.js uses a very different approach, instead of handling parallel execution through threads, it handles it through a mechanism called the Event Loop, by never blocking and delegating works that involves waiting.
What Is Event Loop ?
In general, we can assume the event loop as a smart and tireless task manager, which runs a continuous check of :
Check if the call stack is empty or is JavaScript currently executing anything?
If the stack is empty, check the queues are there any callbacks waiting to be run?
If there are, pick the highest-priority one and push it onto the call stack for execution.
Repeat this forever until the program ends.
We can understand the flow of event loop with below diagram :

This event loop, never sleeps, never blocks, it never waits, and never does any computation itself. It is purely an orchestrator, constantly checking, picking, and dispatching.
Why Node.js Needs An Event Loop
Without the event loop :
Every request will blovk the thread
No parallel handling of user
Poor perfomrance and scalabiliy
With the event loop:
Non-blocking execution
Faster response handling
Efficient resource usage
Two Pillers Of The Event Loop :
To understand the Event Loop deeply, we need to understand the two data structures event loop bridges:
Call Stack
Task Queue
Call Stack :
The call stack is the area where the Javascript functions actually executes. It works like a stack of items, whichever comes last, goes out first ( LIFO : Last in First out ).
When a function is called, a new frame is pushed onto the top of the call stack, when it returns, the frame is popped off. This stack can only process one frame at a time, and it processes them synchronously from top to bottom. If a function takes 3 seconds to complete, the entire stack is frozen for those 3 seconds.
Task Queue :
The task queue, aslo called the callback queue is a waiting room for async callbacks, when an async operation completes, a timer fires, a file finishes reading, a network response arrives. It's callback is placed here. The queue works on the approach of FIFO : First in First out.
Crucially, callbacks in this queue do nothing until the event loop picks them up and the call stack is empty.
These two structures form the backbone of everything async in Node.js. The call stack is where work happens right now. The task queue is where work waits to happen later. The event loop is what connects them.
How Async Operations Really Work :
When you call async function like setTimeout, fs.readFile or fetch, Node.js does not pause and wait for it to finish, It hands off the work to libuv.
libuv is C library, which works with Node.js that interface directly with the Operating System's async APIs.
libuv manages a thread pool for I/O-heavy work and uses OS-level event notification systems (like epoll on Linux or kqueue on macOS) to know when operations complete.
This means the Node.js JavaScript thread is free to keep running while libuv handles the heavy lifting in the background. When the OS reports that an operation is done, libuv puts the callback into the appropriate queue. The event loop picks it up the next time the call stack is clear.
console.log("Start");
// 1. Pushed onto stack, runs immediately
setTimeout(() => {
console.log("Timer done");
}, 2000);
// 3. Runs AFTER the stack is empty (not "after 2 seconds" exactly)
console.log("End");
// 2. Pushed onto stack, runs immediately
1 Start
2 End
3 Timer done
What happens step by step: console.log("Start") runs synchronously. setTimeout is encountered : Node immediately registers the timer with libuv and moves on without waiting. console.log("End") runs synchronously.
Now the stack is empty. After 2 seconds, libuv places the timer callback in the queue. The event loop detects the empty stack, picks the callback, and runs it. Only then does "Timer done" print.
Timers vs I/O Callbacks
Node.js handles different types of async operations in separate queues, and understanding the difference between the two main categories is important.
Timers :
setTimeout() and setInterval() are time-based. Their callbacks enter the timer queue after a specified minimum delay has elapsed. "Minimum" is important here, if the event loop is busy processing something else when the timer fires, the callback waits until the current work is done. You can't guarantee exact timing with these.
I/O Callbacks
File reads, database queries, HTTP requests etc. these are completion-based. Their callbacks fire when the OS reports the operation is finished, regardless of time. A fast SSD might complete a file read in microseconds; a slow network request might take 5 seconds. The callback fires when it's ready, not on a clock.
The key conceptual difference: timers depend on time passing, I/O depends on something external finishing. Both go through libuv, and both end up in queues that the event loop manages, but they live in different queues with different priorities.
Queue Priority (The Order That Matters)
Not all queues are treated equally by the event loop. Every single "tick" of the loop, it processes queues in a strict, defined order.
| Queue | Description |
|---|---|
| Microtask | Promise.then() and process.nextTick(). These run first, and the entire microtask queue is drained completely before moving on to anything else. This means a long chain of resolved promises can delay timers and I/O callbacks. |
| Timers | setTimeout() and setInterval() callbacks whose delay has elapsed. Processed after all microtasks are done for this tick. |
| I/O | Callbacks from file system operations, network requests, database queries. Run after timers in the same loop cycle. |
| Check | setImmediate() callbacks. These are designed to run right after I/O callbacks in the same loop iteration — useful when you want something to run "after I/O but before the next timer check." |
| Close | Cleanup callbacks, for example, a socket.on('close', ...) handler. These run last in each cycle. |
Microtasks always cut the queue. A resolved Promise.then() will always run before any setTimeout(fn, 0), even if both are ready at the same time.
Role of Event Loop in Scalability
All of this design has a powerful payoff. Because Node.js never creates a new thread per request, the memory cost of concurrency is dramatically lower than traditional servers.
10,000 concurrent connections in Node.js = 10,000 callbacks in a queue, not 10,000 threads eating RAM.
No thread synchronization required — one thread means no race conditions in your application code.
I/O operations never block the main thread — while one request waits for a DB query, the event loop is already handling the next request.
Startup is fast, memory footprint stays lean even under heavy traffic.
This is why Node.js is the go-to choice for real-time applications (chat, live notifications, multiplayer games), REST APIs that are I/O-bound rather than CPU-bound, and streaming services where thousands of open connections must be maintained simultaneously.
Real World Analogy
Here's a mental model that maps the whole system to something familiar.
| Queue | Role Comparision | Working |
|---|---|---|
| Call Stack | The Chef | Can only cook one dish at a time. Fully focused on the current task — nothing else happens while the chef is cooking. |
| Task Queue | The Order Tickets | Completed orders pile up here, waiting to be picked up. The kitchen doesn't stop taking orders just because there's a queue. |
| Event loop | The Manager | Watches the chef and the ticket rail constantly. The moment the chef is free, the manager hands over the next ticket. |
The manager (event loop) never cooks and never takes food to tables. They just keep the kitchen running — the instant the chef (call stack) finishes one dish, the manager hands them the next ticket (callback). And when the kitchen is completely empty and quiet, the manager stands by the door waiting for the next customer order to arrive — that's the event loop blocking on the OS when all queues are empty, waiting for new I/O events.




