Inside Git: How It Works
Most of the developers use Git everyday. We type git add, git commit, git push almost without thinking. Over time, these commands become habits, but the understading stays unclear.
In this article we are going to change that.
Instead of focusing on commands, we will understand how Git works internally, why the .git folder exists, and how git safely track our code.
The main goal of this article is not memorization, but building a clear mental model of Git.
How Git Works Internally
Git is a system that stores snapshots of our project. Each snapshot represent how our entire project looked at a specific moment in time. Git stores current state of files and connect those states together using references.
Understanding the .git Folder
When we run the git init command, Git creates a hidden folder called .git. This folder is the most important part of the repository.
Our project files stays outside this folder, but everything needed for the Git to know our project, lives inside this folder. That includes commit history, branches, tags and configurations. If the .git folder is deleted, Git has no memory of our project’s history.
We can think of the .git folder as Git’s private storage area, or a database that it manages automatically.
Why the .git Folder Exists
Git needs a place to store information in a structured and safe way. The .git folder exists so Git can save file versions, connect commits together, verify data integrity, and keep track of branches.
With the help of this folder, Git can answer questions like :
What did this project look like yesterday?
Which commit belongs to which branch?
Has any data been corrupted?
Existance of .git folder is very crucial for any project, if there is no git folder there are no history of the project.
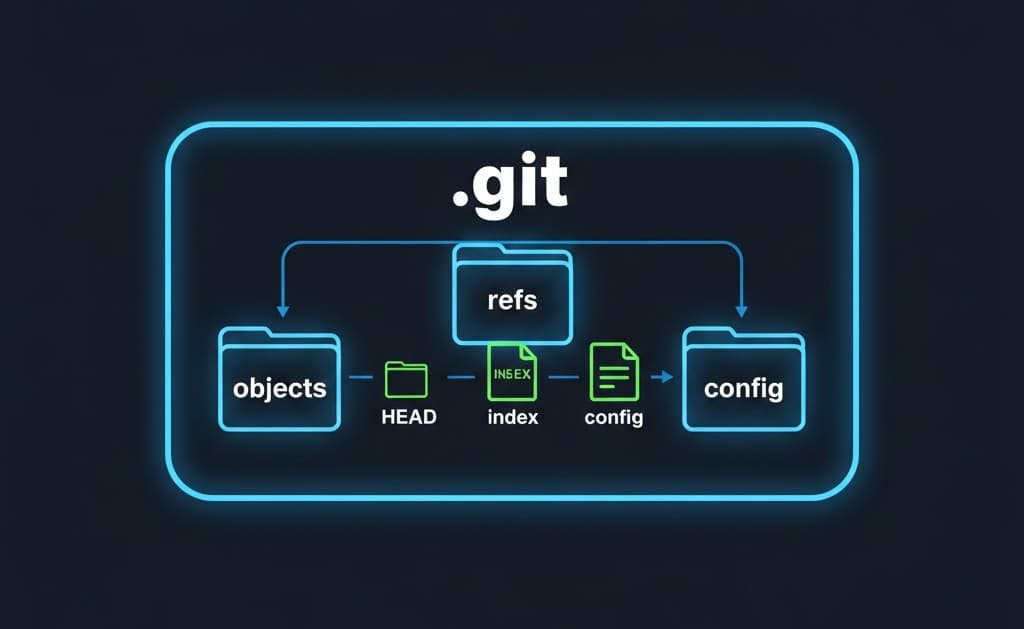
Structure of .git Directory
Inside .git folder, there are multiple files and folders. At first this structure may look confusing, but few of them are needed to understand how Git works.
The most important directory is objects. This is where Git stores all the actual data like file contents, folder structures and commits. Other important files include Head, which tells Git where we currently are, and index which acts as the staging area.
We need to understand objects properly, to understand most of the Git’s behaviour.
Git Objects: Blob, Tree and Commit
Git stores everything as objects. There are only three main object types, and each one has a clear responsibility.
A Blob stores the content of a file. It does not store the file name or its location, but only the raw data. If two files have the same content, Git stores only one blob and reuses it.
A Tree represents the structure of directories and files, It connects file names to blobs and folders to other trees. In simple terms, a tree describes how files are arranged.
A Commit represents a snapshot of the project. It points to a tree and also stores information such as the author, commit message, and a reference to the previous commit. Every commit stores a previous version of the project.

How Git Tracks Changes
Git does not track changes directly. Instead, it creates new objects only when content is different. If a file stays the same, Git keeps pointing to the old blob.
Because of this approach, Git saves space and avoids unnecessary duplication. This is one of the main reasons Git performs so well even with long histories.
Internal Flows of Git Commands
We know the flow of Git, which looks like this :

Now we will understand what these commands do internally.
What Happens Internally During git add :
When we run git add, Git reads the content of the file and converts it into a blob object. That blob is stored inside the .git/object folder. At the same time Git updates the index, which is also known as staging area.
At this stage, no commit is created. Git is only preparing data and marking it as ready for the next snapshot.

What Happens Internally During git commit :
When you run git commit, Git takes the data from the staging area and builds a snapshot. It creates tree objects to represent the folder structure and then creates a commit object that points to that tree.
Finally, Git updates HEAD so it points to this new commit. At this moment, history is written and the snapshot becomes part of the repository permanently.

How Git Uses Hashes to Ensure Safety
Every object in Git is stored using a hash generated from its content. This hash uniquely identifies the data and changes if the content changes.
Because of this system, Git can detect corruption and prevent silent data modification. This design is a main reason why Git is trusted for critical and large-scale projects.
Building the Right Mental Model
Instead of thinking that Git “stores changes,” it is more accurate to think that Git stores snapshots made of objects.
The .git folder acts as a database. Blobs store file content, trees store structure, commits store snapshots, and hashes guarantee integrity. Once this mental model is clear, Git commands feel less magical and more logical.





